CQRS is too complicated
Published on 2011-9-28
Is something I hear all too often at conferences and on Twitter, and more often or not it is said because of either a basic misunderstanding of what CQRS is or is not - or perhaps because they've dipped their toes into the hyperactive DDDCQRS mailing list and been scared away by all the white coat discussion that goes on in there a lot of the time.
The other day, the sentiment was yet again voiced by somebody of whose opinion I respect on Twitter and I ended up in about five minutes writing a gist explaining why I didn't think this was the case (Writing 4000 word essays is an hour's work if I'm feeling ranty), I've tidied it up a bit and decided to throw it below as it works well in a blog entry.
A basic summary
At the highest level CQRS just means maintaining a happy division between the reads and writes across your system - that is, having the reads in your system executed in a thin clean manner appropriate to the views you want to retrieve (one model), and your writes going through all the crazy logic you need such as validation, updating queues, third party systems, processing business rules (another model)
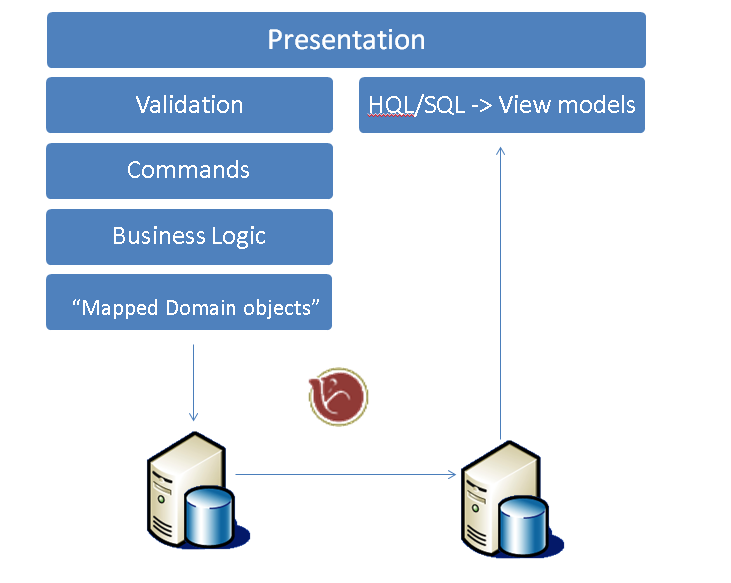
Consider the traditional and very-tongue-in-cheek N-Tier architecture I have created here in powerpoint, seen in a million "architecture" presentations in ASP.NET webforms shops across the world:
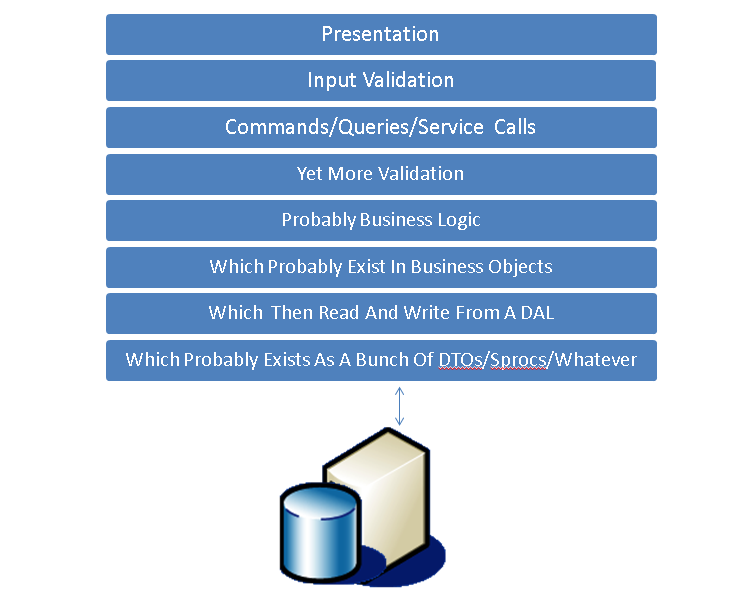
Now modify it a little bit so that our reads haven't got to go through all that cruft, haven't got to somehow amene themselves to a bunch of "DAL objects" that are created with the very best intention of standardising our access to some form of database (and normally optimised for the write actions anyway).
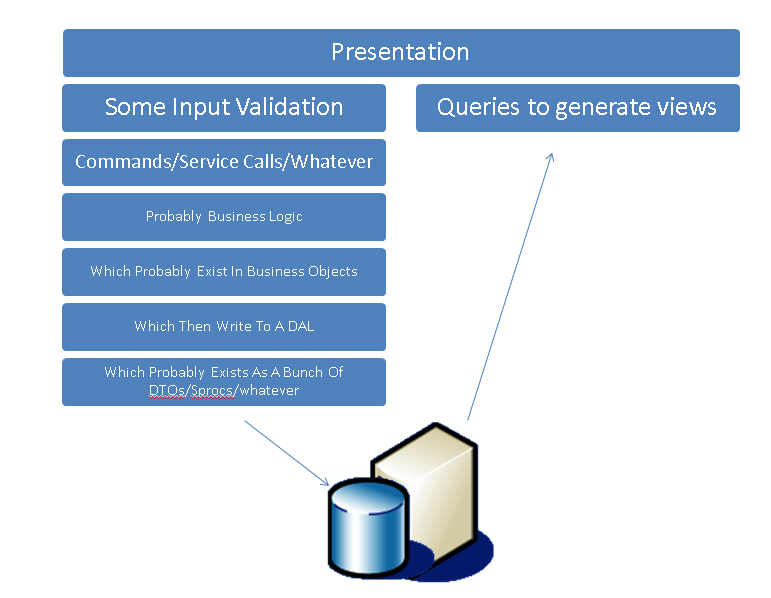
We can instantly make our lives a lot easier by creating a pile of code optimised for creating views for our presentation layer, perhaps doing a bit of raw SQL or calling a sproc to generate the view for us. We can helpfully formalise this arrangement and for the most part set down a rule that the direction of travel down those two paths is one way (towards the DB for writes and away from the DB for reads). Funnily enough - most systems that do that BOL/BLL/DAL/OCKS stuff end up with something that looks like this anyway because it's too hard to do everything through a single model.
This is now a form of CQRS - at the highest level we've effectively split our system into two models and done something that's very similar to what we'd call CQS if we were doing it at the method level. This in itself should surely be enough to convince you that CQRS itself is not complicated and it might be a useful thing to look further into.
Of course, as you go further down the rabbit hole...
Some examples
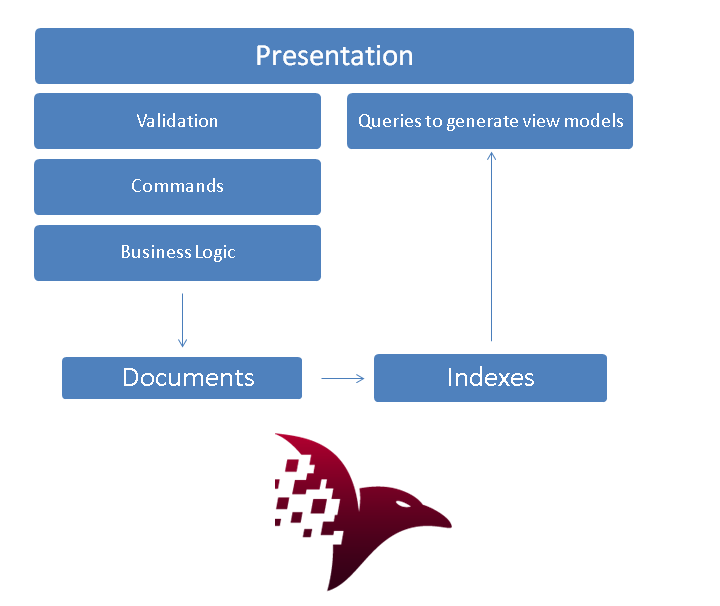
CQRS can be achieved by using a document database like Raven or Couch - using your documents as a write store, using your indexes as a query store.
It can be achieved with your favourite ORM (Even better if you can actually use that O and that M and get some good old OO going) - if you want to use your objects for encapsulating business logic and go directly to the the queries to project the data you need for views (HQL, SQL directly, SPROCS, whatever) - from the same database even, providing this remains efficient enough for your needs. (Funnily enough, "our" collective weak attempts at creating domain models with NHibernate are what led to us re-discovering the need for two models in the first place in my opinion).
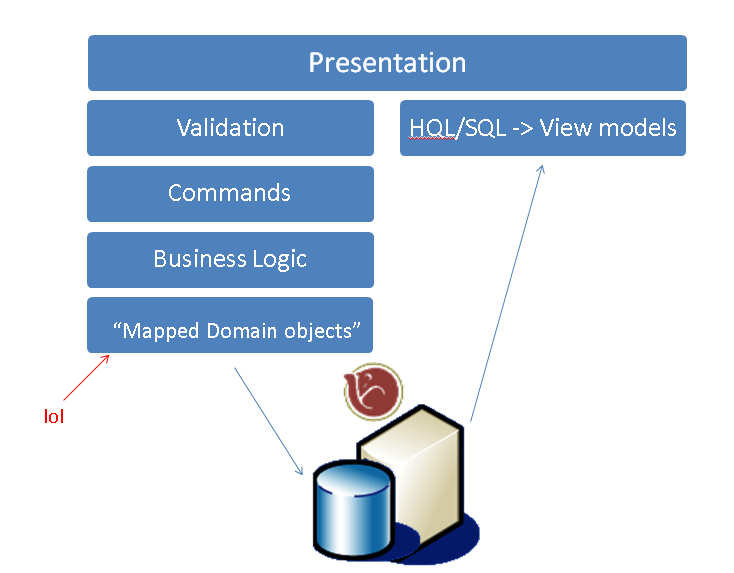
Of course you may well end up with two databases anyway, as trying to query a database comprised of tables that represent state in your "objects" can be pretty inefficient, with the read store updated from the write store using hooks in your write system to generate pre-calculated views or data that's more applicable to generating views - this is not a bad model and can work too, it's still CQRS.
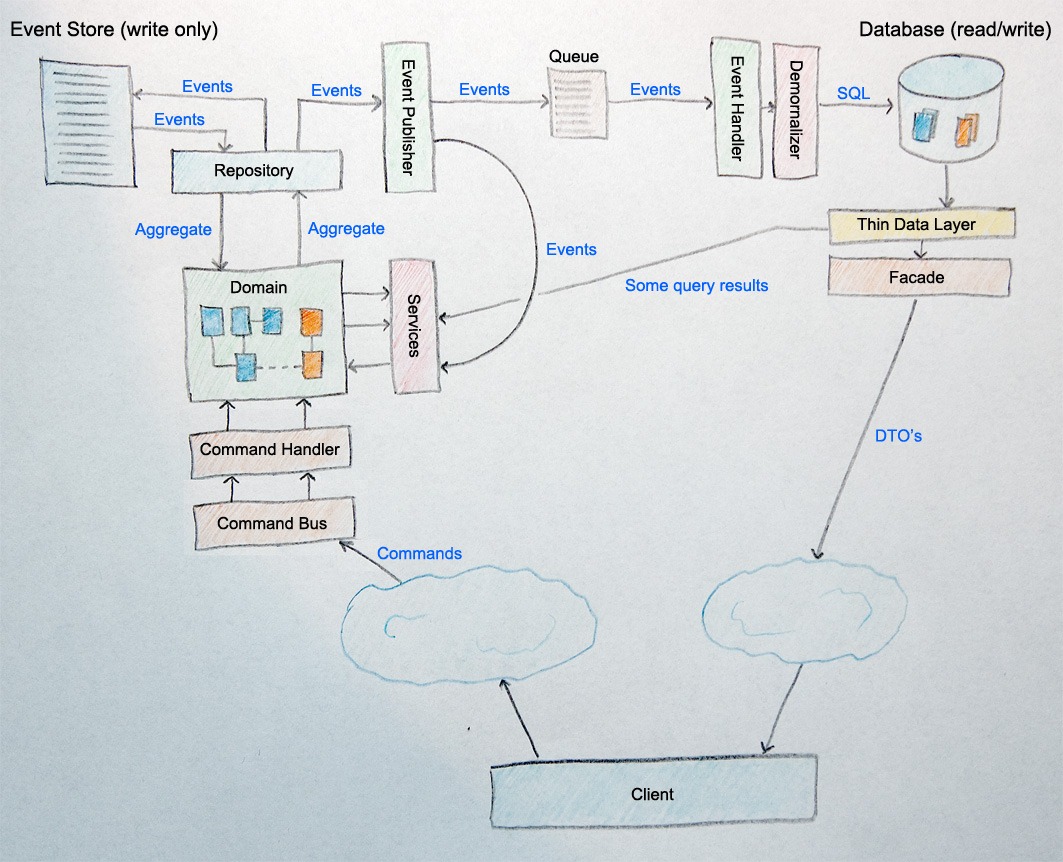
CQRS gets the "complicated" label because people often associate it directly with event sourcing, which requires that little bit more of up-front development in order to get the level of elegance you won't find in the above scenarios. However, even event sourcing is really simple once you look at it - and is a natural progression from some of the other ways of "doing" CQRS - which can be a bit muddy (not that there is anything wrong with systems that are a bit muddy). Note that I'm not mentioning DDD here At All - which is where a lot of heavy learning lies, and nearly none of us do anyway.
Consider hooking those events in your system to manually flatten/re-arrange data into other stores as outlined above? Does that work for that one other store? How about a reporting store? How about full text search? What about integration with third party systems and the data they want to see from you? How about the boardroom reports your CEO now wants on his desk each morning before he starts his day?
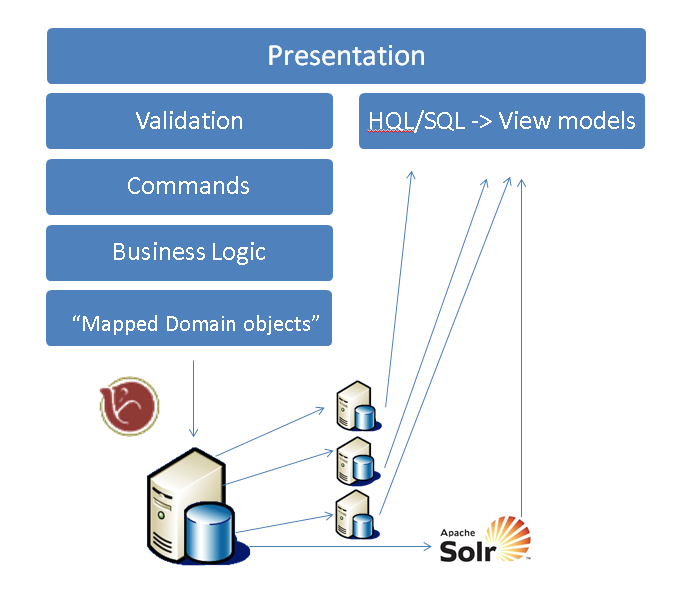
Youch. Deciding your single source of truth is the already written state gives you an amount of inflexibility, which you may or may not be happy with up to a point.
Updating other views of this truth after small changes can be inefficient and awkward. Recovering after introducing any write bugs to the system can be expensive also. Hell - even changing your model can also be expensive as database migrations are hardly the easiest things if you're trying to work with multiple stores and layers all over the place. When your powerpoint presentations start looking like this you have complexity issues- and these complexity issues aren't caused by CQRS, they're caused by having complex powerpont presentations.
Moving to events and jumping through a few hoops to make this possible can open up a world of simplicity, and if it's not for you there are other options open to you. CQRS is not complicated - trying to shoehorn the responsibilities of read and write through a single model is complicated. Most of us realise that going through a standard "BLL, DAL, BOL, TLA, CRA, P) layer for both reads/writes is dumb, and CQRS is a good way of formalising this decision.
Another tdlr;
You can see that clearly there is a natural progression from the very basics to having the need to go for a full blown event sourcing system with publishers/subscribers/servers/eventual consistency once the complexity of trying to manage a more "simple" solution starts to overwhelm.
Unless you have that complexity and that need then of course trying to thrust an ivory tower designed architecture onto a system that doesn't need it is going to seem complicated. Hint: If your technical solution is more complicated than your original problem you're probably doing it wrong.
2020 © Rob Ashton. ALL Rights Reserved.