The use of Clojure in the CDEC Open Health Data Platform
Published on 2013-9-9
I'm currently at Mastodon C where I am learning new stuff, both for the pleasure of learning and also to pick up skills that will be useful to my clients in the future - I am also blogging about this in a series which has entries queued up for the next few weeks.
As part of my time here, I am contributing work to the CDEC Open Health Data Platform, and came across a blog entry which suggested that the use of Clojure for this platform was a bad fit for a number of reasons.
So, putting the queued up blog entries to one side, and posting out of phase halfway through my work here I wish to respond to the article, based on my own experiences and interpretation of the project. (I am not speaking for Mastodon, as any regular reader will know my words are always my own and I can't write things any other way!)
The industry lacks the experience required to contribute to the CDEC platform
This is the primary assertion made to question the use of Clojure in this platform. It is made off the back of a number of searches being made on indeed.co.uk, which resulted in less than a 1% hit rate for that technology.
I am always uncomfortable when people classify developers or themselves as either "Java developers" or "C# developers" as if the years of experience they have in those areas aren't going to help when moving to other platforms. I've feel that it massively undervalues their actual experience to qualify it with a single attribute in that way.
This feels like an extension of that somehow, because it fails to take into account people's abilility to learn new things based on previous experience.
My own experience with Clojure/Cascalog
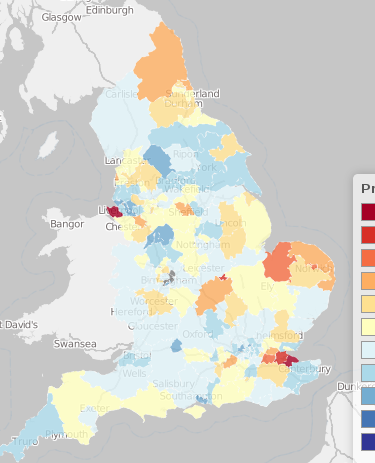
I am reluctant to draw on my own anecdotal experience because it's very easy to dismiss such things, but I wish to make the point that I am exactly the sort of person that will be found looking for .NET development jobs on a site like indeed.co.uk. I am the person who (used to) have a LinkedIn account littered with key-words for .NET and JavaScript and nothing else.
My own experience is as such that I don't have any experience on the JVM (the runtime on which Clojure is built on), I've never looked at Hadoop in my life and I spent a few evenings trying to write Clojure in order to learn it before making the leap to attempting to contribute to the Open Health Data Platform. In essence, I am one of the least qualified people (going on sites like LinkedIn/Indeed) to be working on this platform.
Within a few days I feel as if I've made substantial progress being able to find the data sets, process them through cascalog, aggregate and join various aspects of this data and generate some meaningful results off of this. (See image to the left). The information available on the internet on the subject is plentiful, freely open and the community is welcoming of questions about how to work on things.
The intern's experience with Cascalog and Clojure
I am not the first to tread down this path either, before me was Anna Pawlicka, who wrote a large amount of code in the current codebase as part of her internship at Mastodon.
The code works great, and she wrote an entry of her own experiences. Although I have not spoken to Anna, her experiences seem to mirror my own in terms of getting working productively in this environment for the first time.
Experience is more than just key-words
While this evidence is only anecdotal; it maps cleanly onto what I have learned in my years of software development - that developers can learn new things when necessary and that the choice of a very good technology shouldn't be overlooked because folk don't have it on their CV yet.
The need for a higher level of abstraction
This is another closing point made in the original blog entry, that the current stack itself is too low level for the majority of the R&D community to be getting involved with.
I'd be wary of such endevours because most of my enterprise experience has been about striving for higher levels of abstraction in order that the majority of some community can get involved with a product or business intelligence efforts. Invariably this has taken place in environments where the vast majority of the actual users are competent Excel users, and we end up replacing a powerful tool (Excel) with some less powerful and less flexible replica of excel written in a costly platform.
Far better in my opinion to be bringing the researchers with the training and the developers with the experience together in order to create knowledge, rather than spend time trying to create potentially costly abstraction.
While I am not saying that some level of automation or workflow assistance aren't ultimately desirable, It would be remiss of the project coordinators to let this desire override the basic need for the power to ask the questions that are needed over the top of the data provided.
The thing about data, is that the questions we want to ask tend to be very different across different data sets, and we tend to be better off looking at how other people have solved similar problems and re-implementing these approaches for the specific domain under question.
Cascalog seems to be a perfect level of abstraction for dealing with these data-sets, with enough power to do anything wanted and enough magic to hide the technological problems away from the developer.
In closing
I am excited about the Open Health Data Platform and its purpose, and I am excited about the technology being used.
Like the original author, I am also excited about the way in which this project is being developed in the open and pushed out on regular intervals forfeedback such as that.
I have four more days left at Mastodon (out of a total of 5 so far), and hopefully I can contribute many more examples to the project between now and then to help other people follow in these footsteps in the future!
2020 © Rob Ashton. ALL Rights Reserved.